MRI Dementia PredictionCurrently, there are 50 million people living with some form of dementia(World Health Organization). While there is no known cure for dementia, there are multiple factors that can lessen the impact of the condition. These factors include, diet, exercise, mental stimulation, cardiovascular health, and sleep.
Can we use MRI and lifestyle data to detect early onset Alzheimer’s in individuals by examining MRI data such as volumetric measurements, cortical thickness, lifestyle habits, dementia rating, brain volume, and functional connectivity.
Background & Prior Work
Currently there are 50 million people living with some form of Alzheimer's or some form of dementia [^World Health Organization]. While there is not currently no known cure, there are a few factors that can help lessen the impact of the condition including Diet, exercise, mental stimulation, cardiovascular health, and sleep [^WHO]. But the earlier the condition is caught, the more effect these attributes can be to minimizing the deteriorating condition.
A patient with a genetic predisposition to Alzheimer’s would benefit from routine checkups that would serve as a way to measure the progression of the disease. The check ups would include gathering data like brain scans, blood panels, mental fitness, diet, exercise frequency, substance use, and so on. A model can be built using this data that would serve as a predictor of the patient's future given their current lifestyle choice, thus influencing them in one way or another.
We can use CNN’s to classify MRI data [^Zahraa et. al] and thus help make some sort of prediction on the future progression of the disease. We will then attempt to extend these classifying techniques to include the lifestyle data[^Cochran at al], as well as dimensionality reduction in the case of irrelevant data within our dataset.
[^WHO]: (15 March 2023) Dementia. World Health Organization https://www.who.int/news-room/fact-sheets/detail/dementia
[^Zahraa et al]: (31 March 2022) Automatic Classification of Alzheimer's Disease using brain MRI data and deep Convolutional Neural Networks https://arxiv.org/abs/2204.00068
[^Cochrane et al]: (2 Jun 2020) Application of Machine Learning to Predict the Risk of Alzheimer's Disease: An Accurate and Practical Solution for Early Diagnostics https://arxiv.org/abs/2006.08702
Hypothesis
We believe that proper analysis of MRI data can provide important insights into the early detection and progression/prevention of Alzheimer’s disease. Early detection of Alzheimer’s using MRI data can be achieved by analyzing factors such as volumetric measurements, cortical thickness, white matter integrity, dementia rating, brain volume, and functional connectivity.
Using these markers we can classify subtle brain alterations to make predictions based on the patient’s future outcomes.
Data
1. Cross-sectional MRI Data in Young, Middle Aged, Nondemented and Demented Older Adults: This set consists of a cross-sectional collection of 416 subjects aged 18 to 96. For each subject, 3 or 4 individual T1-weighted MRI scans obtained in single scan sessions are included. The subjects are all right-handed and include both men and women. 100 of the included subjects over the age of 60 have been clinically diagnosed with very mild to moderate Alzheimer’s disease (AD).
-Dataset Name: MRI and Alzheimer's
-Number of observations: 436
2. Longitudinal MRI Data in Nondemented and Demented Older Adults: This set consists of a longitudinal collection of 150 subjects aged 60 to 96. Each subject was scanned on two or more visits, separated by at least one year for a total of 373 imaging sessions. For each subject, 3 or 4 individual T1-weighted MRI scans obtained in single scan sessions are included.
-Dataset Name: MRI and Alzheimer's
-Number of observations: 150
3. Alzheimer MRI Preprocessed Dataset: This data is was collected from several websites/hospitals/public repositories. The dataset consists of Preprocessed MRI (Magnetic Resonance Imaging) images and all the images are resized into 128 x 128 pixels. The dataset has four classes of images and additionally consists of total 6400 MRI images.
Class - 1: Mild Demented (896 images)
Class - 2: Moderate Demented (64 images)
Class - 3: Non Demented (3200 images)
Class - 4: Very Mild Demented (2240 images).
-Dataset Name: Alzheimer MRI Dataset
-Number of observations: 6400 images
Data Analysis
We believe that proper analysis of MRI data can provide important insights into the early detection and progression/prevention of Alzheimer’s disease. Early detection of Alzheimer’s using MRI data can be achieved by analyzing factors such as volumetric measurements, cortical thickness, white matter integrity, dementia rating, brain volume, and functional connectivity.
Using these markers we can classify subtle brain alterations to make predictions based on the patient’s future outcomes.




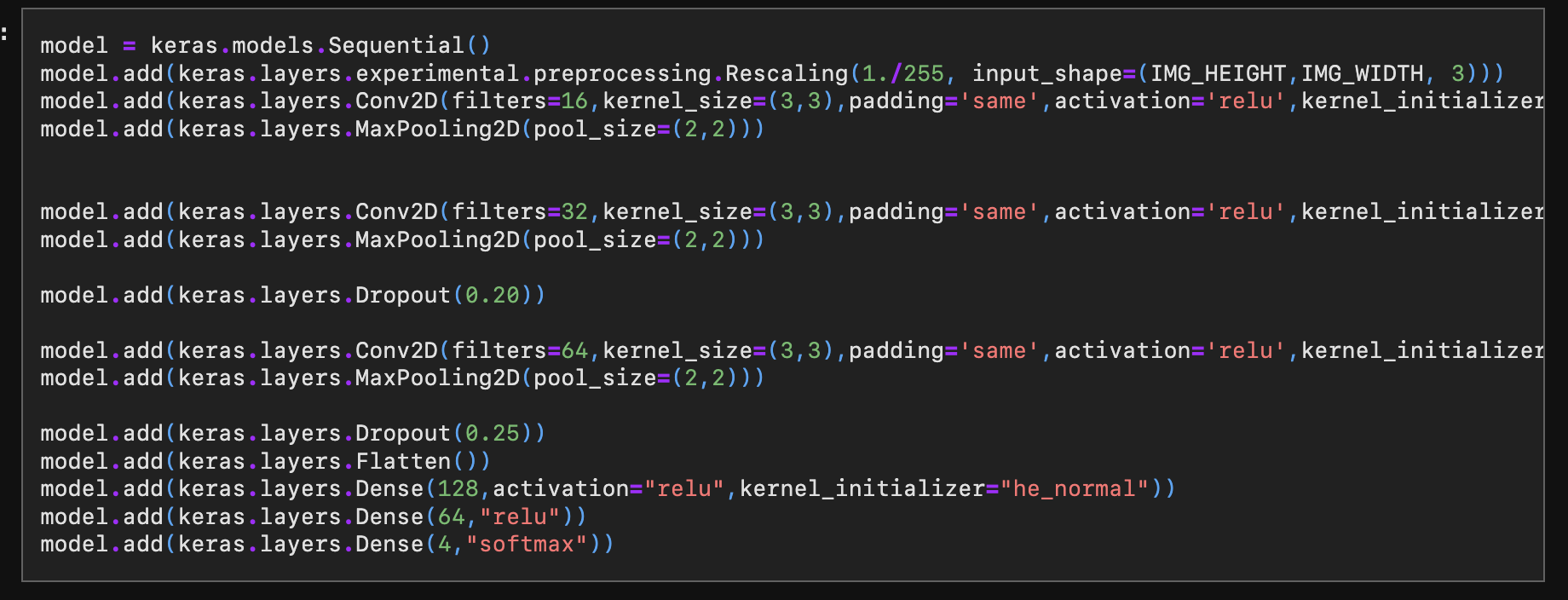
Models
Trying a few different models to see which works best
We are choosing to include a Logistic Regression model as it is a linear classification model that predicts the probability of an instance belonging to a certain class. It can handle binary as well as multiclass classification problems.
Random Forest Classifier model as it is an ensemble learning method that combines multiple decision trees to make predictions. Each tree in the random forest is trained on a random subset of the data and features. It can handle both classification and regression tasks and is known for its ability to handle high-dimensional data and capture complex relationships.
Gradient Boosting Classifier because it is also an ensemble learning method that combines multiple weak prediction models, typically decision trees, to create a strong predictive model. It builds the models sequentially, where each subsequent model focuses on correcting the mistakes made by the previous models. Gradient boosting is known for its high accuracy and ability to handle complex datasets.
And finally a Support Vector Classifier because it is a supervised machine learning algorithm that uses support vectors to perform classification tasks. It finds the optimal hyperplane that best separates the data points of different classes. SVC can handle both linear and non-linear classification problems and is particularly effective in high-dimensional spaces.
We then:

Research Question
Define a function for data augmentation using Sequential model
Create a Sequential model for data augmentation
Add a RandomRotation layer with rotation factor between -0.15 and 0.15
Add a RandomZoom layer with zoom factor between -0.3 and -0.1
Return the data augmentation model
Create the data augmentation model
Assert the properties of the data augmentation layers
Set the input folder path
Create a dictionary to store the count of classes
Calculate the count of files in each class folder
Plot a bar graph to visualize the data imbalance
Set the axis labels
link to full code
Analysis & Results
Discussion
Conclusion & Discussion
"Our original question was 'Can we use MRI & lifestyle data to early detect Alzheimer's?' Given our results from Part 1, to prevent dementia, you would ideally continue to educate yourself throughout life to stimulate your brain, not smoke or drink, eat healthy, and be female. In Part 2, we didn't achieve a great accuracy score, so our classifier is currently no better than flipping a coin. If we had more evenly distributed data, we might be able to train for better results. We were limited in data and, in some cases, computing power. This project was overall very interesting, as so many people are affected by dementia, and we would really like a way to detect it early so that we can try to mitigate the effects."
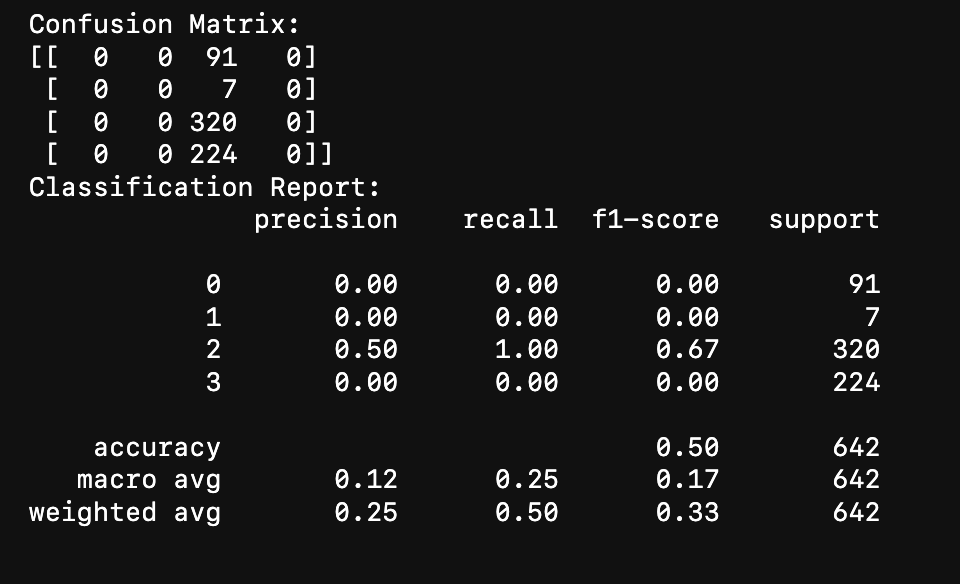
These results suggests that the model struggled to correctly classify samples from classes 0, 1, and 3, while it performed relatively better for class 2. The overall performance of the model on the test set is modest, with an accuracy of 0.50 and varying performance metrics across different classes. I believe it might be due to 2 main factors.
We need more data
We need a more even dataset, our dataset favoured 2 types out of 4.